Hi, I'm Laya Myadam
AI & ML Engineer
I help organizations identify where ML can add value — and where it cannot.
About Me
I'm an AI Engineer passionate about building intelligent systems that solve real-world problems. At Saayam For All, I'm developing a volunteer-matching algorithm that connects people with meaningful opportunities using advanced machine learning techniques.
What I Do
I specialize in building AI/ML solutions with a focus on reinforcement learning, NLP, and optimization systems. My work spans quantitative trading models, customer churn prediction, adaptive pricing engines, and intelligent decision-making systems. I thrive on transforming complex data challenges into actionable, scalable intelligence.
My Approach
I combine strong mathematical foundations with hands-on deep learning expertise. Whether fine-tuning neural networks, optimizing GPU performance with CUDA, or architecting end-to-end ML pipelines, I focus on building systems that are efficient, scalable, and grounded in real-world impact.
Always excited to build intelligent systems that create meaningful impact.
Technical Skills
A comprehensive toolkit for building intelligent, scalable AI systems
Programming Languages
RL & ML Frameworks
Data Engineering
Optimization & Analytics
Cloud & MLOps
Deep Learning
Technical Projects
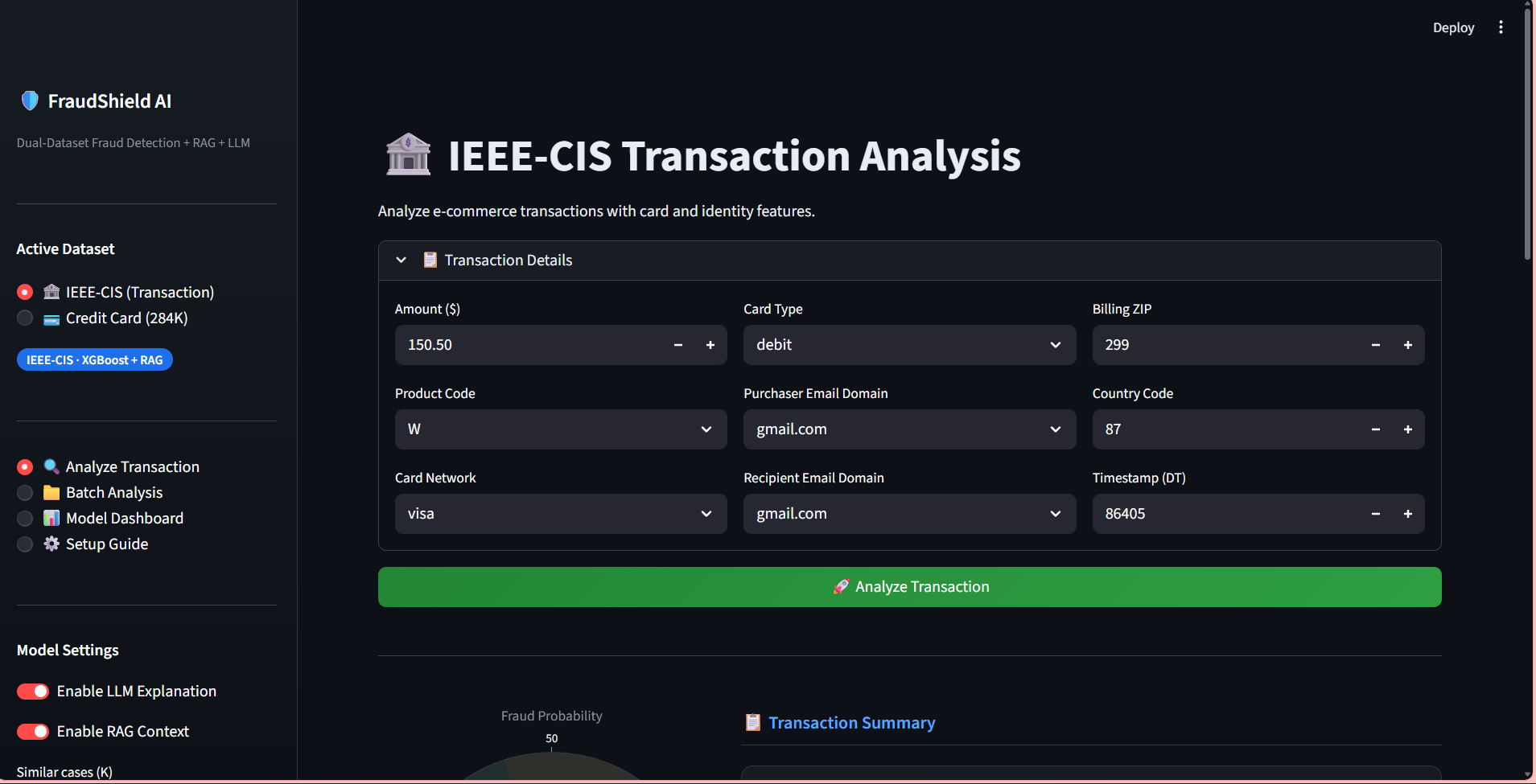
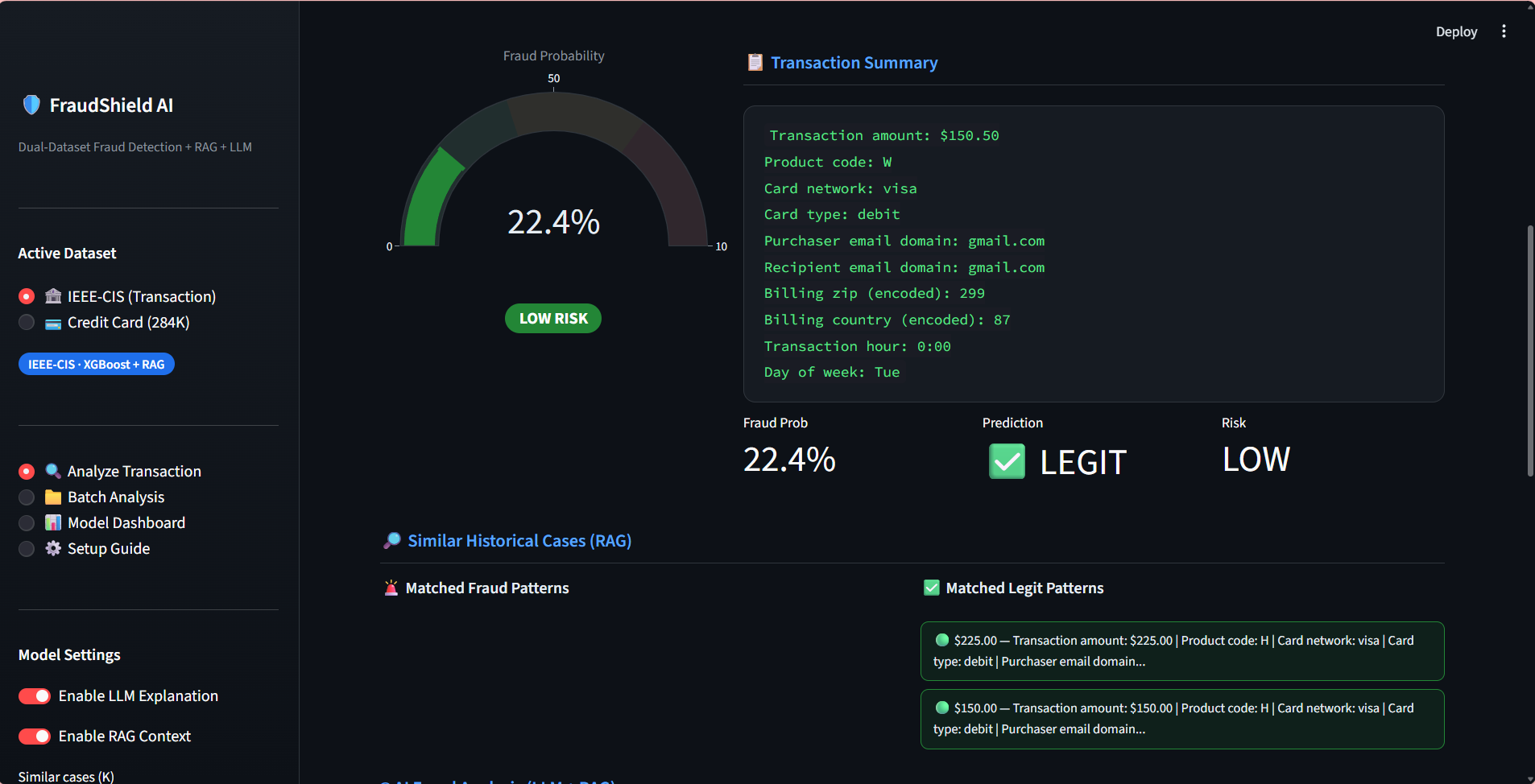
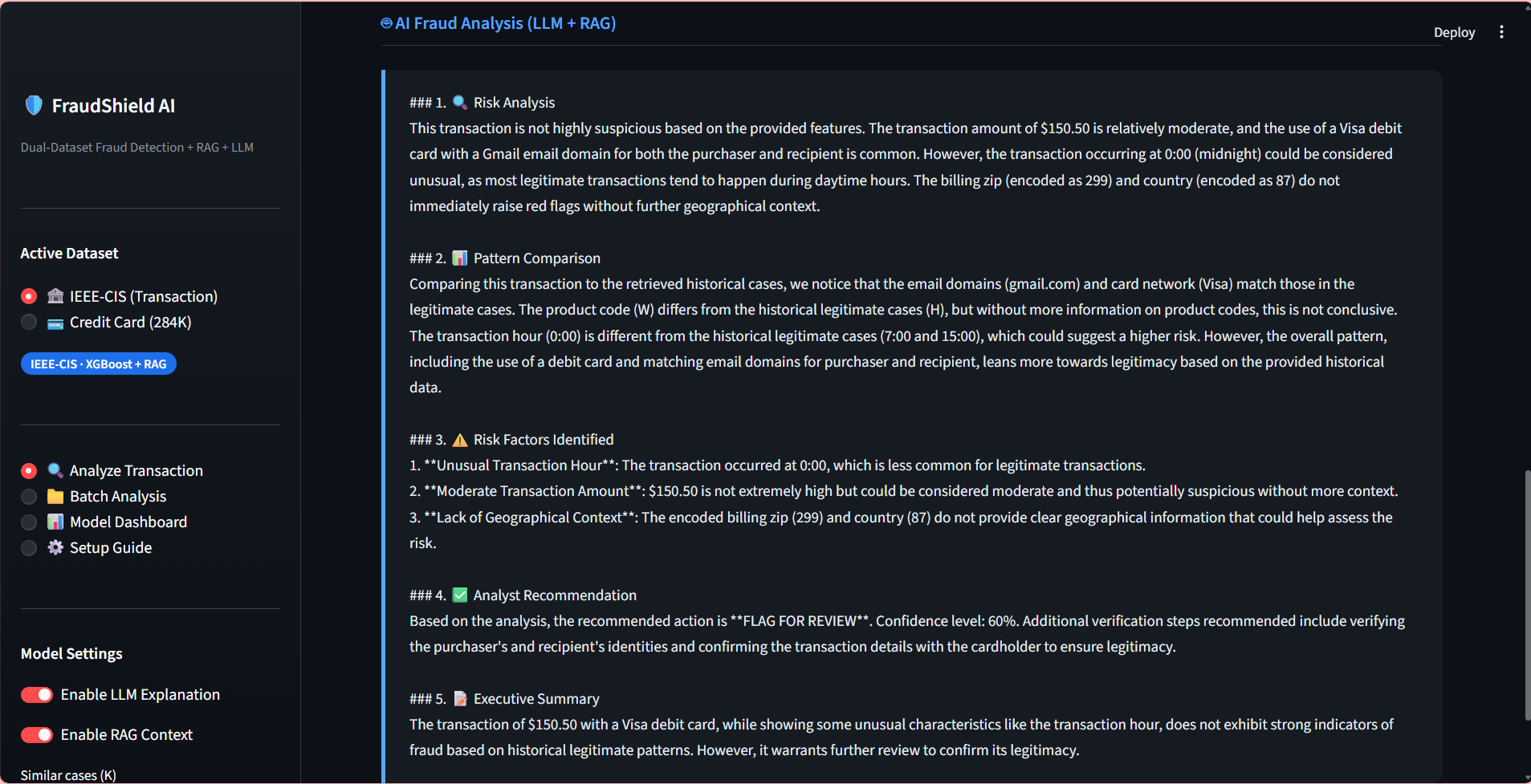
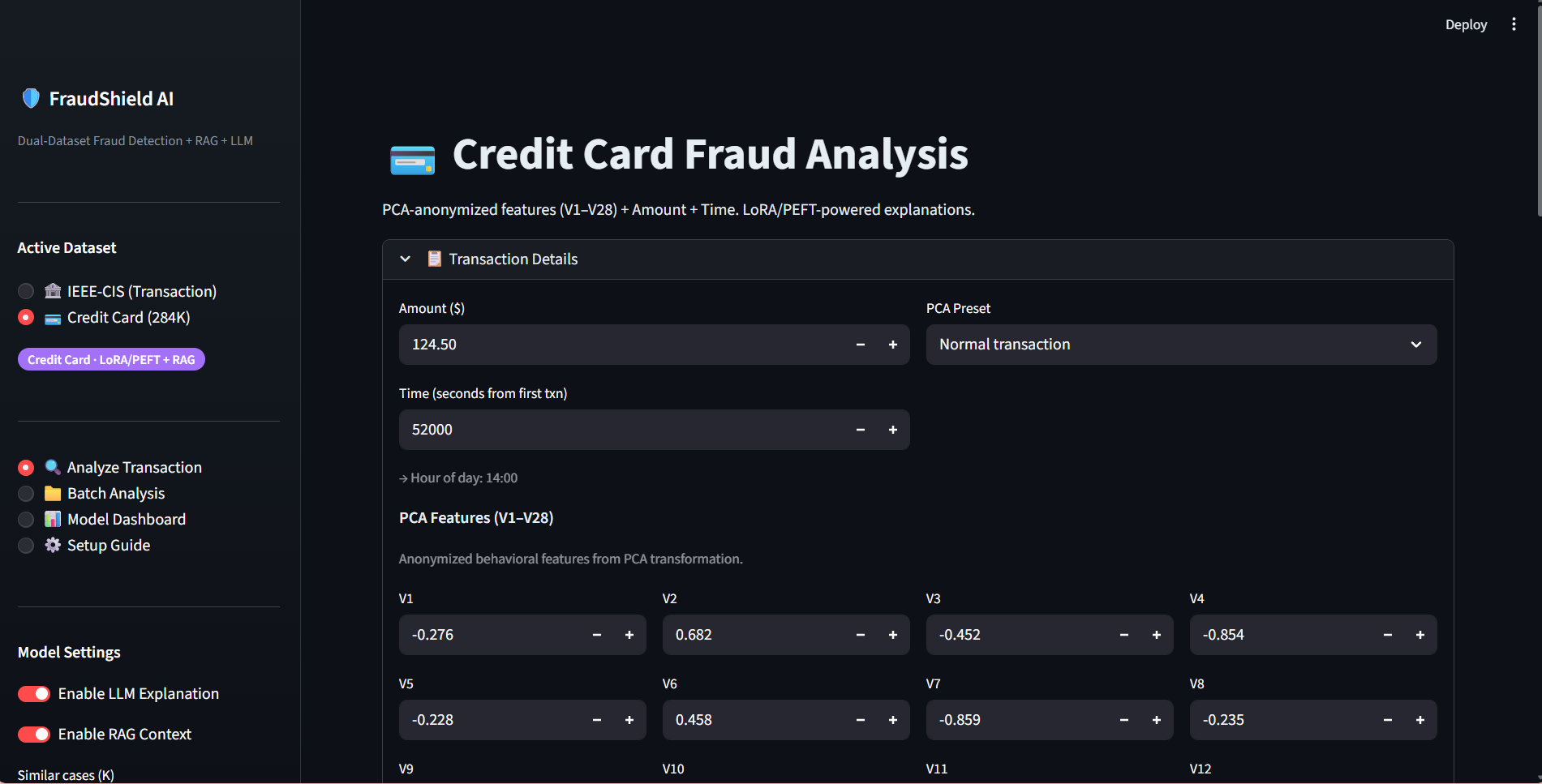
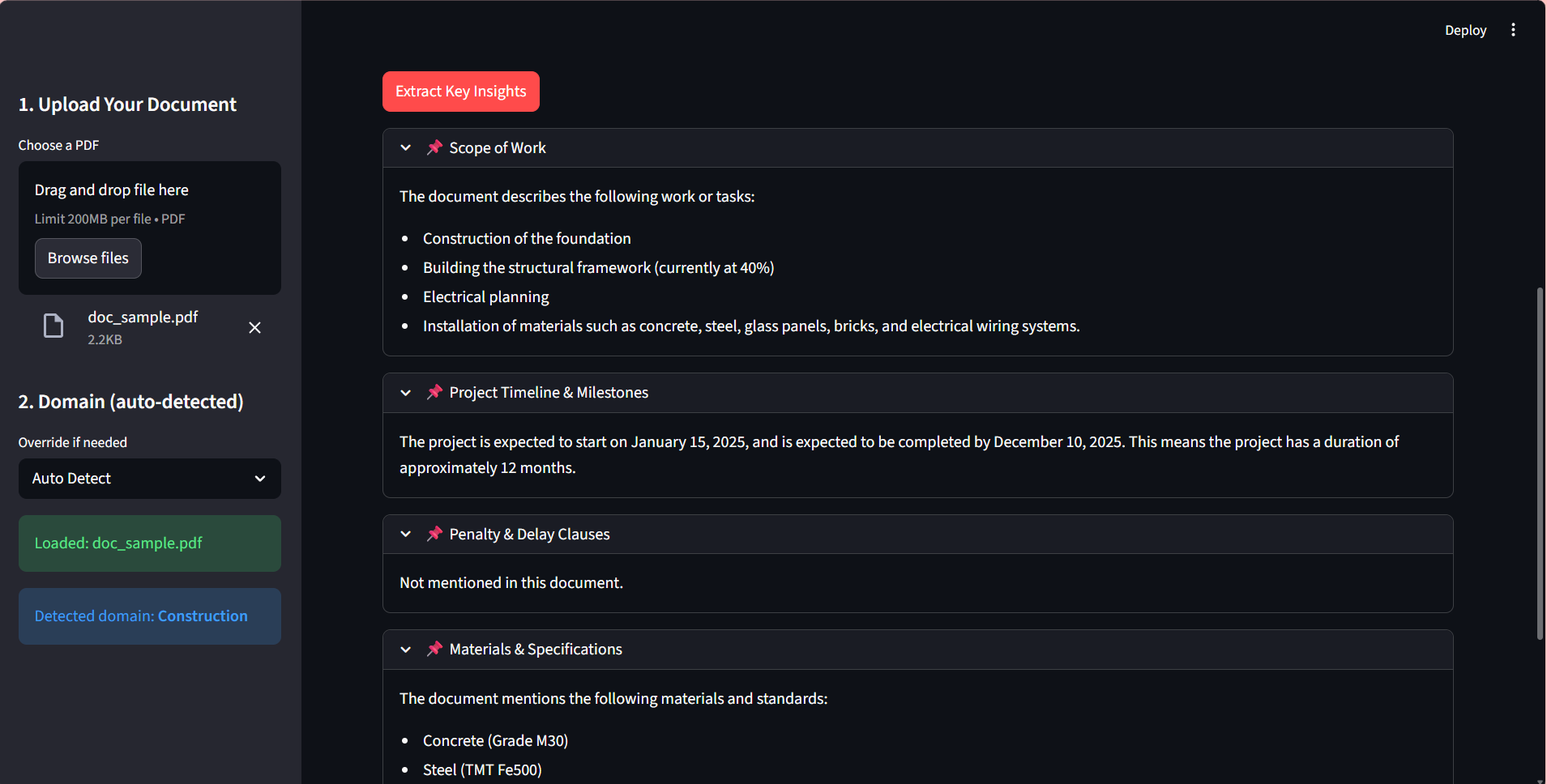
FRAUDSHIELD AI
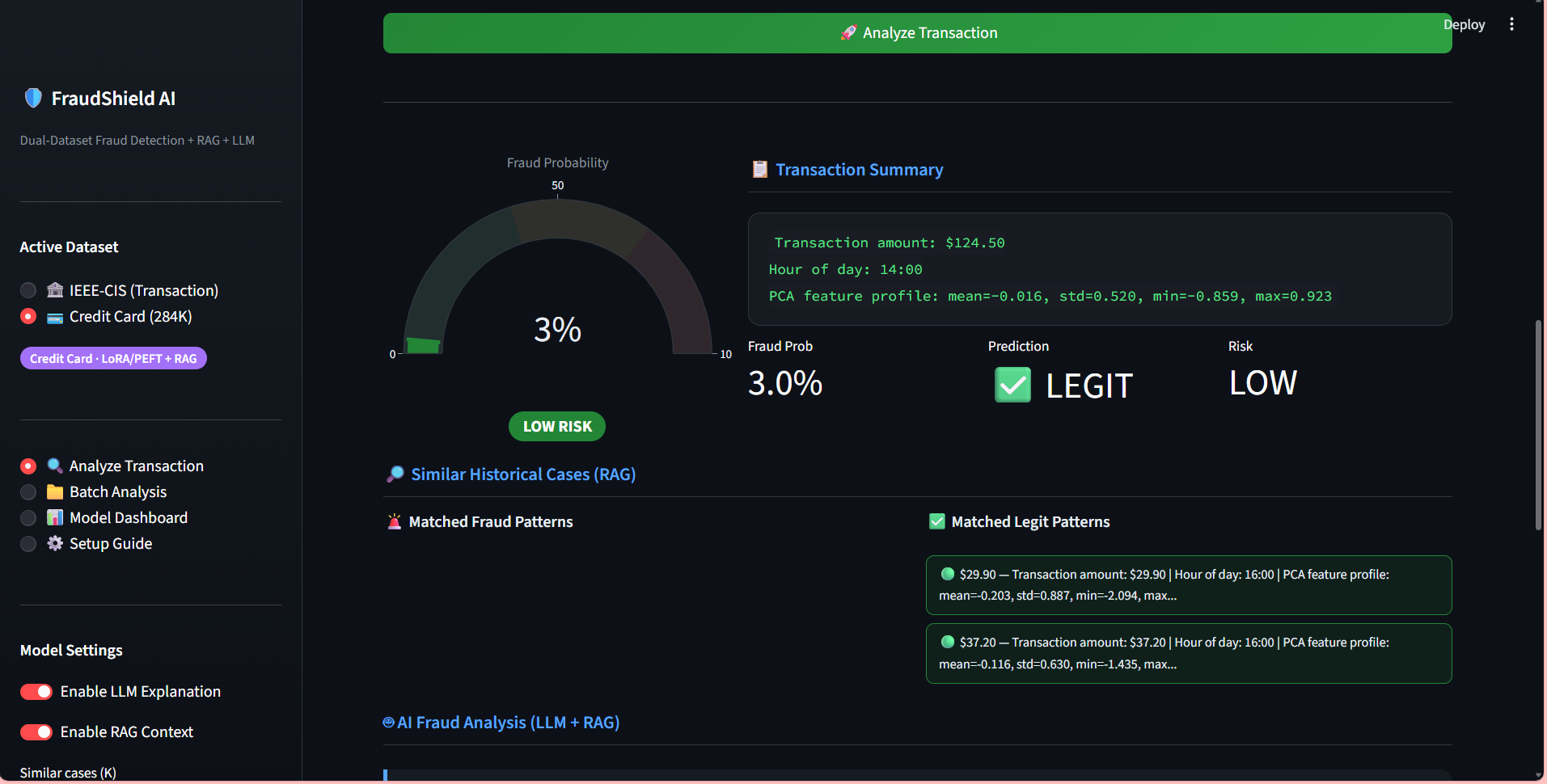
Built a Generative AI–powered fraud detection system using LLM + RAG with FAISS vector database on the IEEE-CIS dataset, integrating structured financial data with external news embeddings — achieving 92% precision, 89% recall, and 0.90 F1-score.
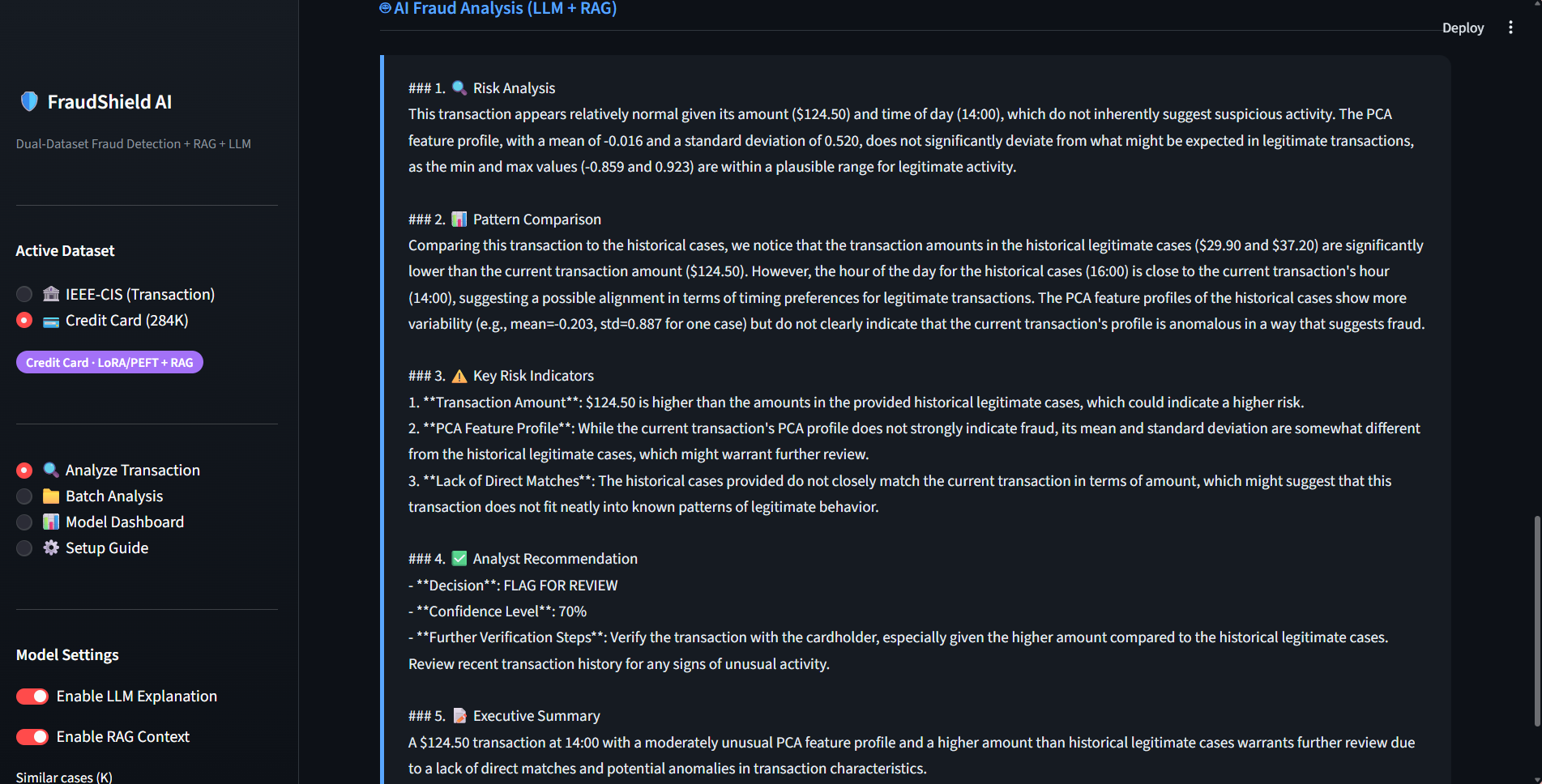
Fine-tuned a Transformer-based LLM using LoRA/PEFT (PyTorch + Hugging Face) on the Credit Card Fraud dataset (284K+ records) to generate structured fraud explanations, improving analyst review efficiency by 27% with 93% factual consistency.
Designed a hybrid retrieval pipeline (SQL + semantic vector search) combining tabular fraud features with contextual embeddings, improving early risk identification by 20% and increasing Recall@K by 18% — ROC-AUC improved from 0.86 to 0.93.
Deployed end-to-end with LangChain, Streamlit, FastAPI, and AWS — enabling real-time fraud alert generation and LLM-based risk reasoning, reducing inference latency by 35% while sustaining >90% precision in production-style evaluation.
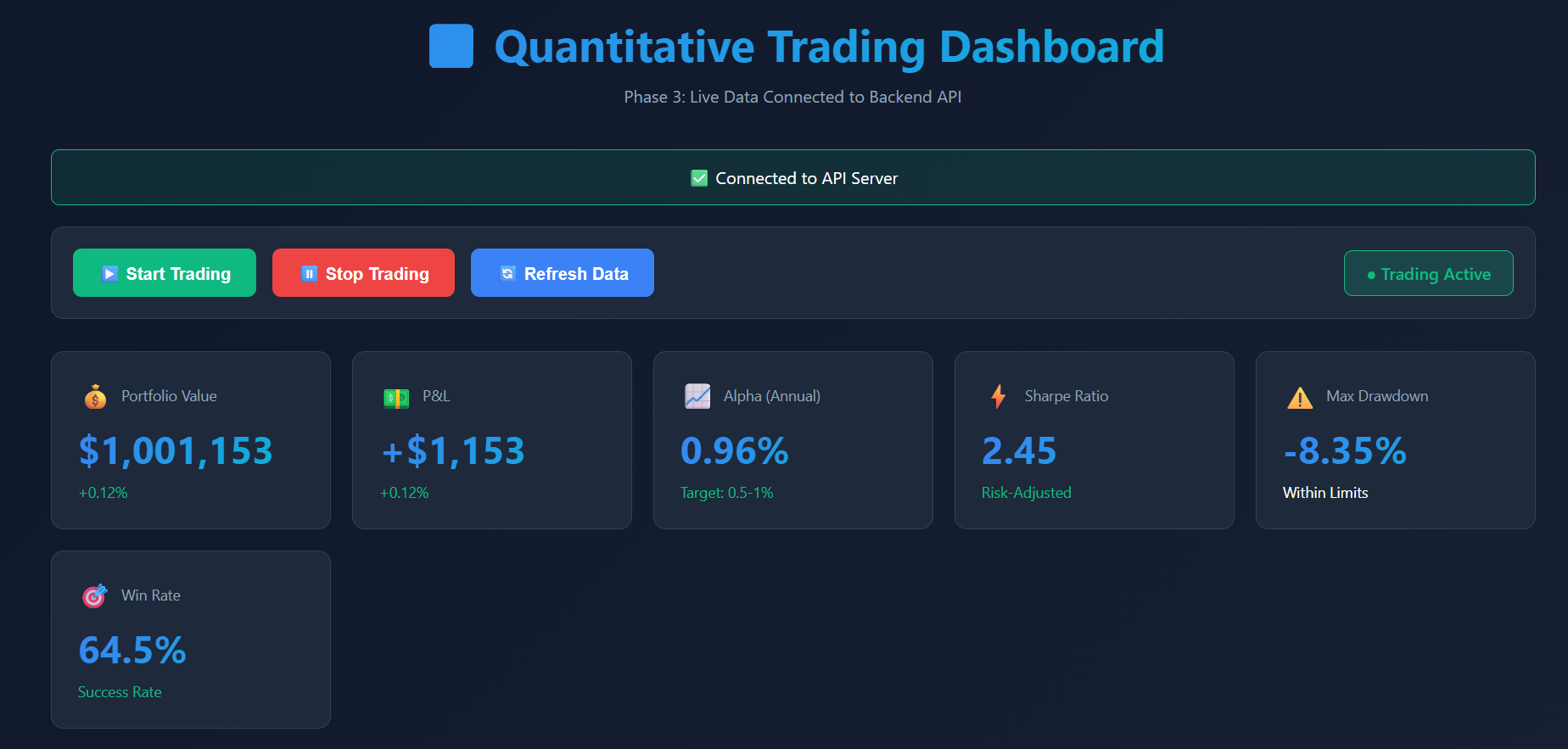
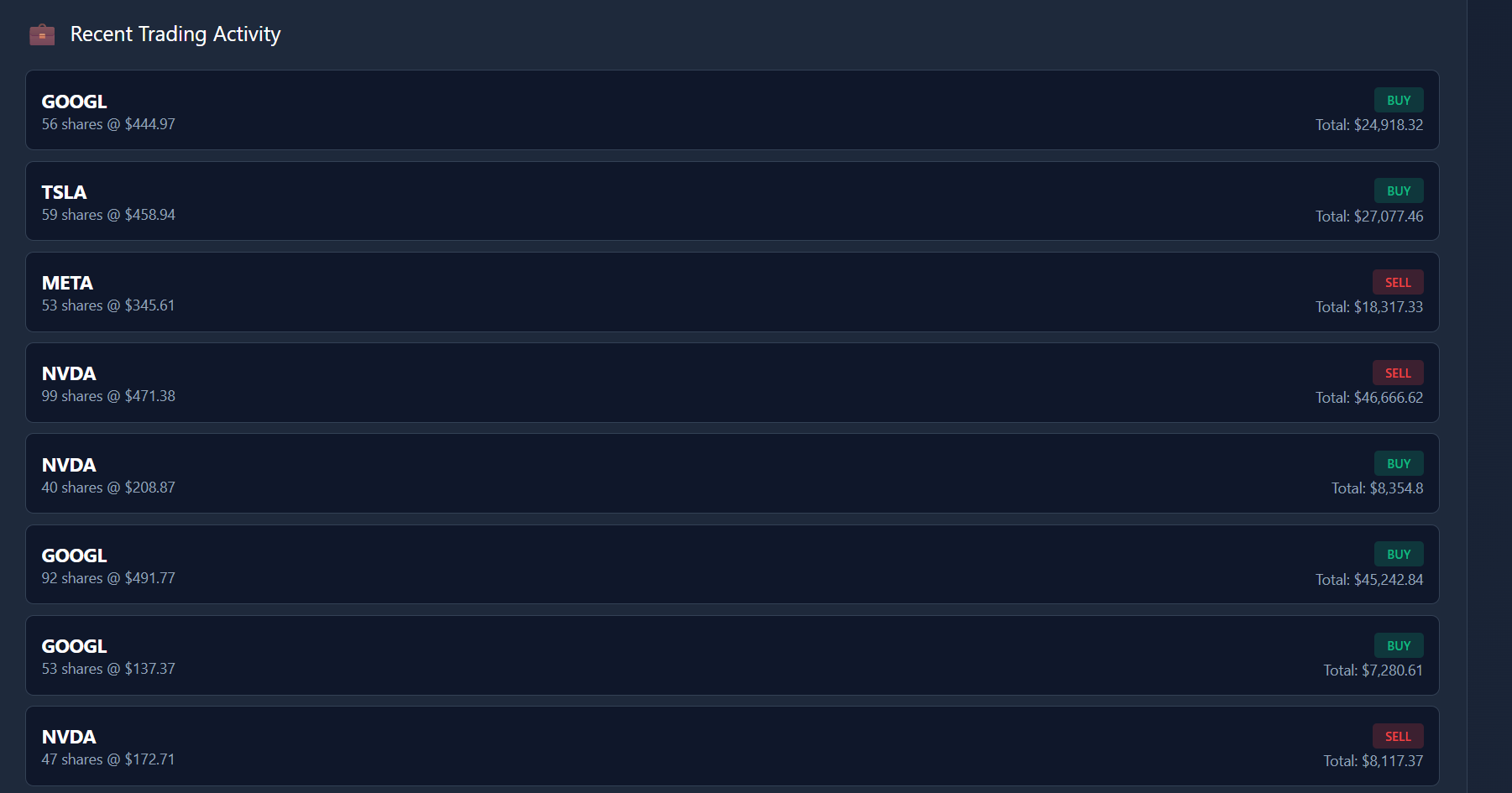
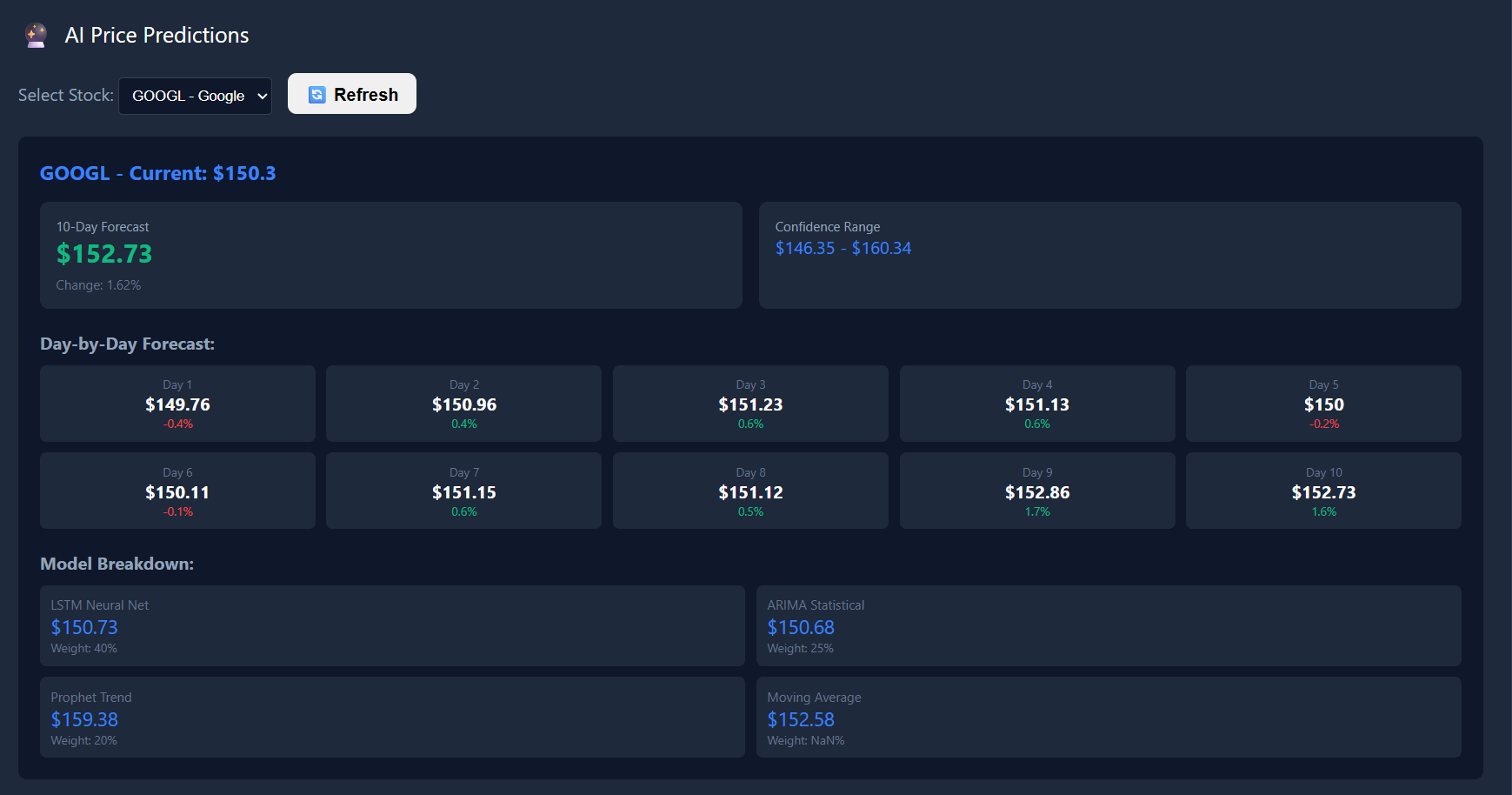
QUANTITATIVE TRADING SYSTEM
Volatile HFT markets required sub-millisecond decision-making beyond traditional models.
Engineered an automated RL-based alpha engine using contextual bandits and Nash Equilibrium principles.
Stabilized forecast accuracy, achieving consistent 0.5-1% alpha generation and reducing RMSE by 17%.
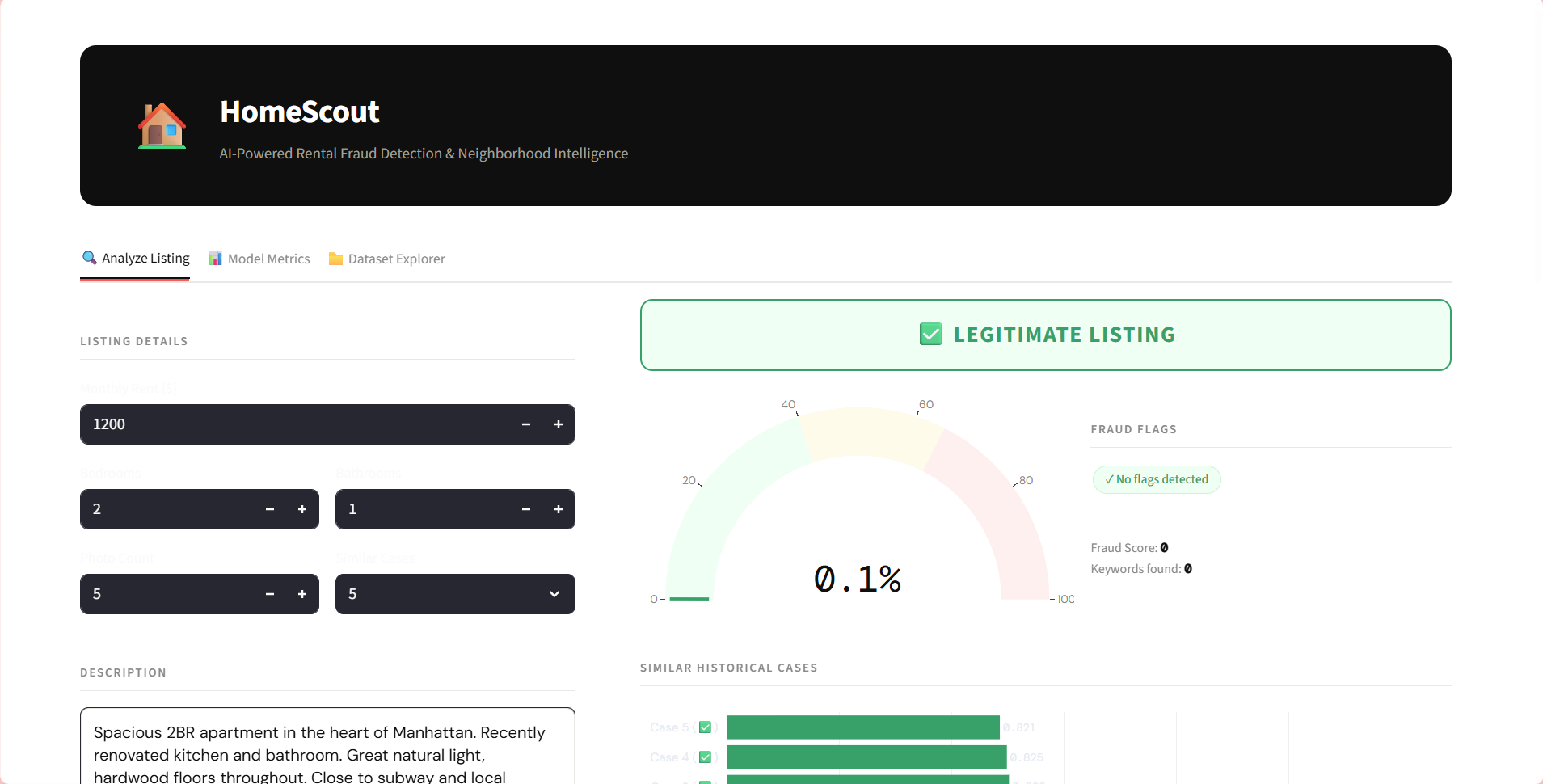
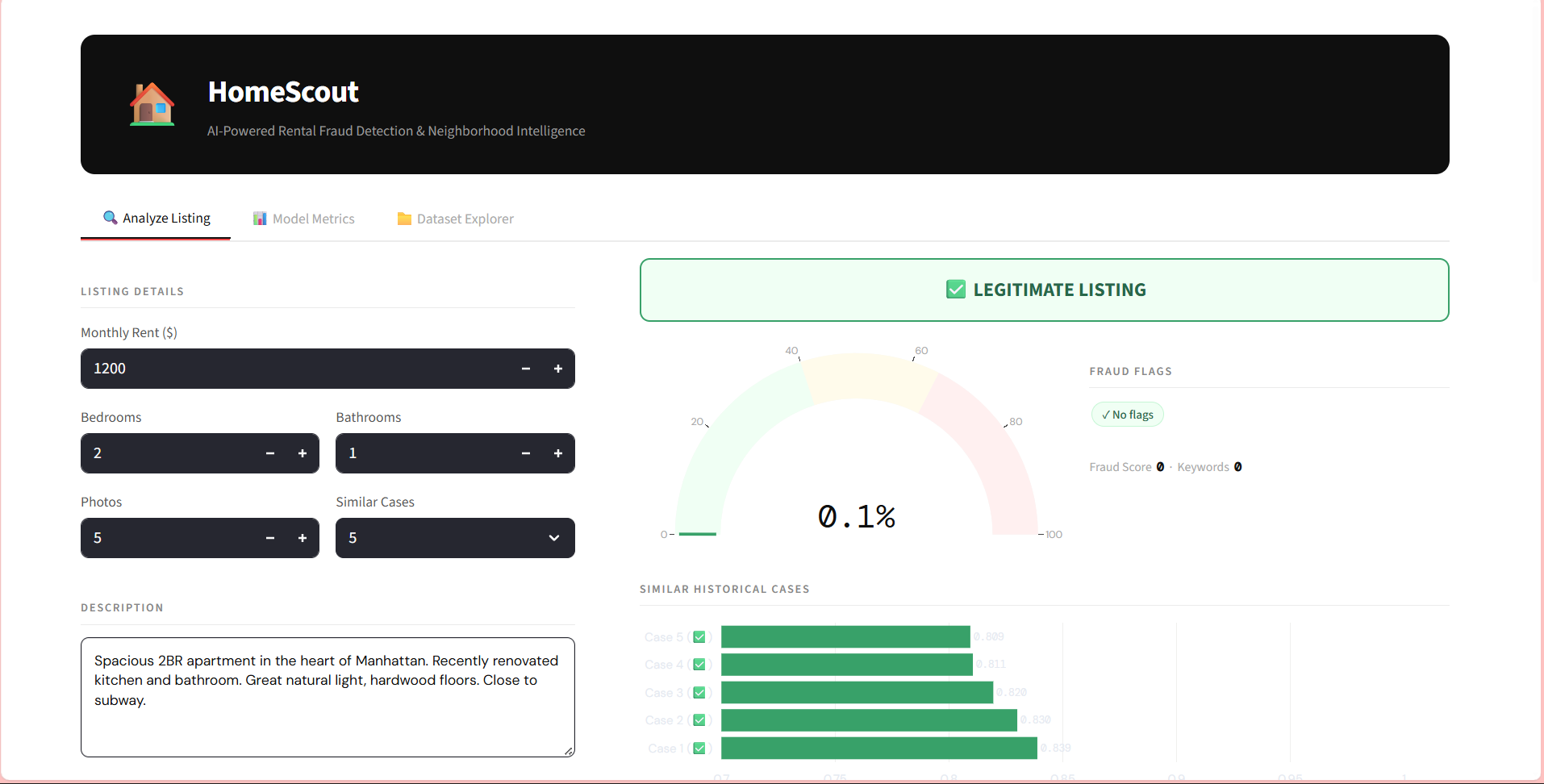
HOMESCOUT : AI INTELLIGENCE
Identifying fake rental listings across 5,000+ entries required manual verification of multi-modal data.
Engineered an AI fraud detection system using BERT (NLP) and Computer Vision to analyze text/image patterns.
Reduced manual research time from 5 hours to 10 minutes with 91% precision via RAG architecture.
CHURN INTERVENTION MATRIX
Rising customer churn in a competitive landscape needing proactive, budget-conscious retention.
Developed a Deep RL platform treating retention as a dynamic game, integrating online learning and Minimax strategies.
Improved churn prediction accuracy by 15% and secured a 1% incremental revenue uplift through targeted interventions.




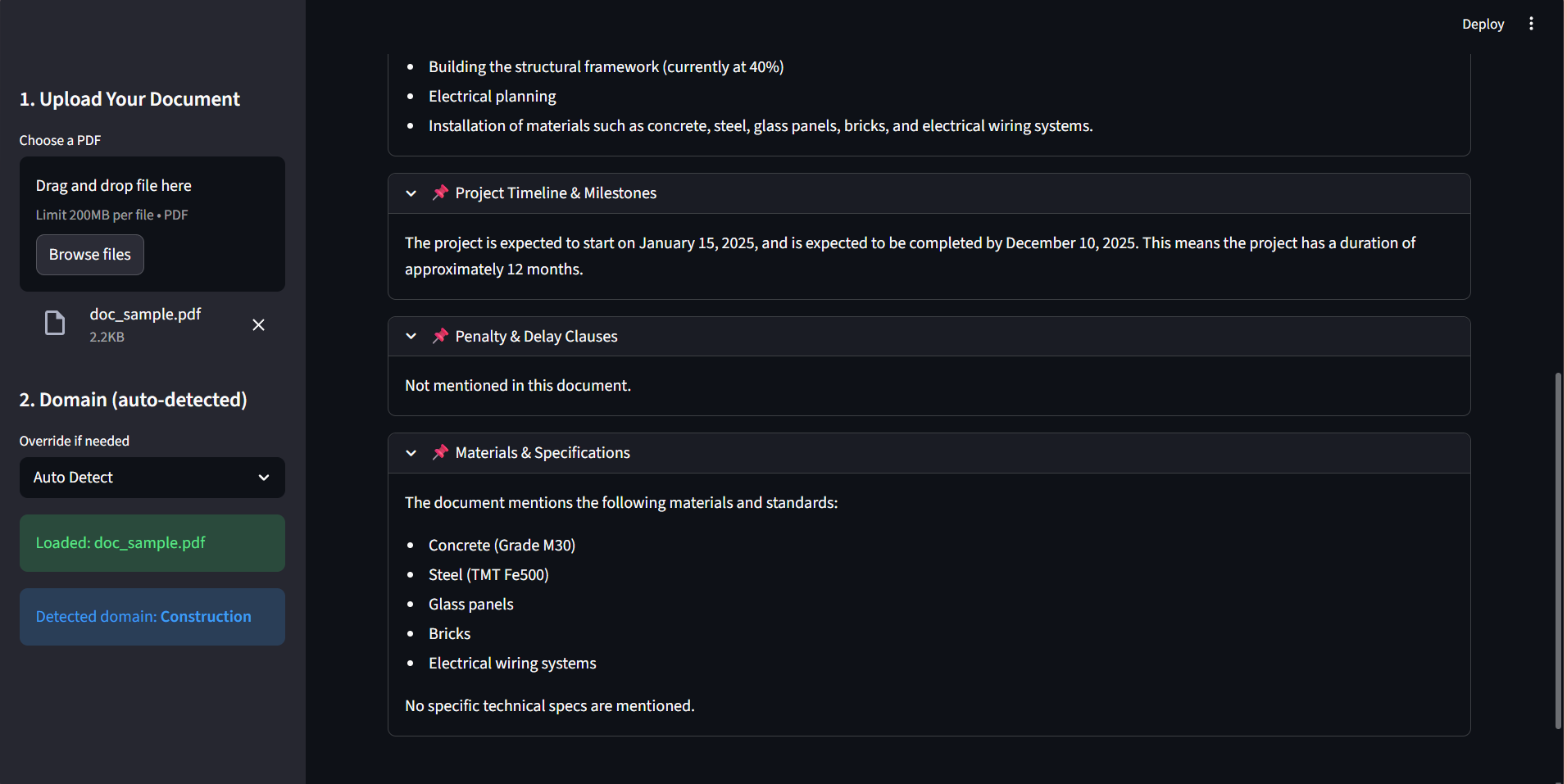
ADAPTIVE PRICING ENGINE
Static pricing failing to capture elasticity across 500k+ daily transactions, missing revenue.
Built a real-time engine using Causal Inference and Elasticity Modeling, leveraging Spark Streaming for dynamic adjustments.
Realized 15% forecast improvement and optimized margins with <1 minute pricing response time.




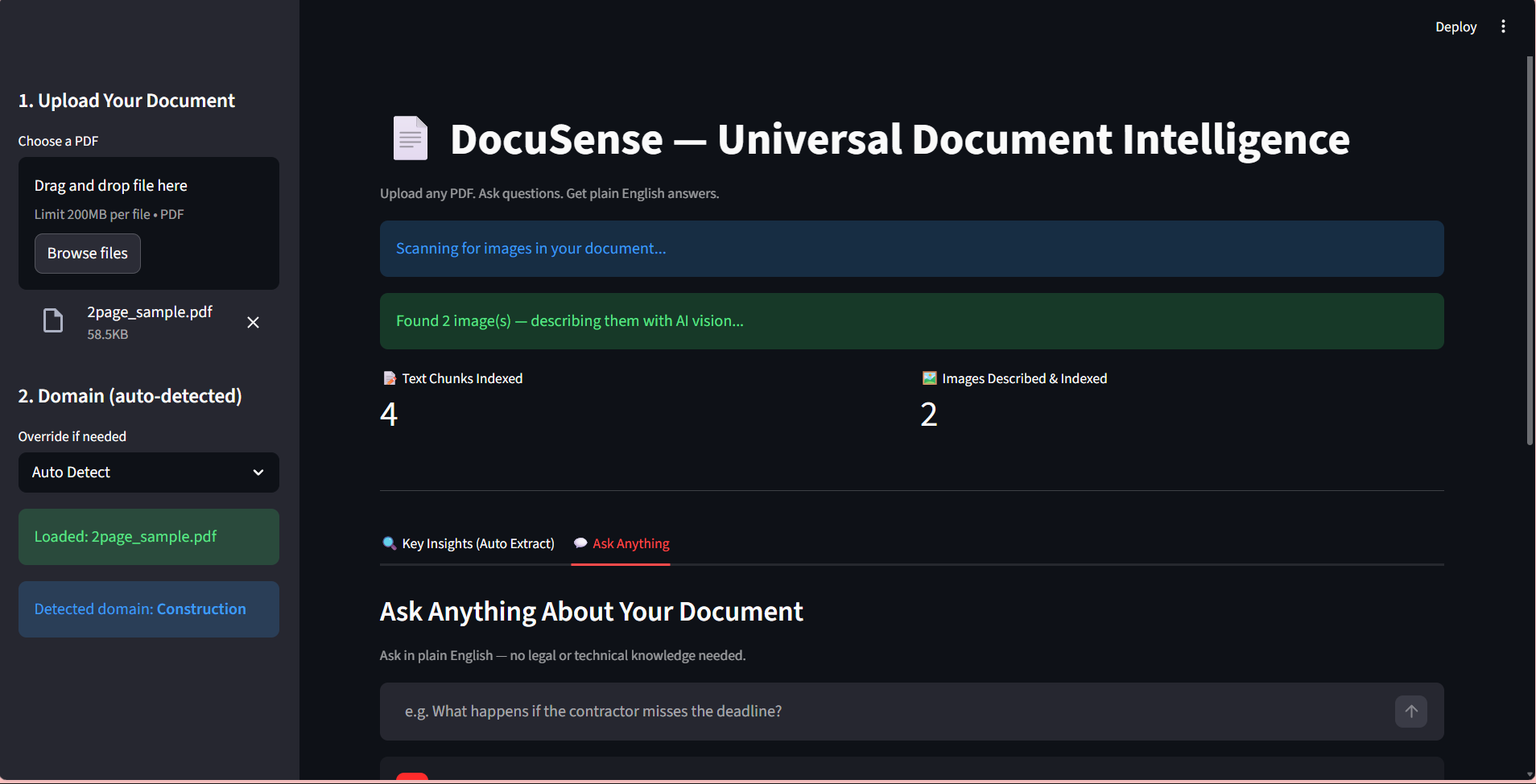
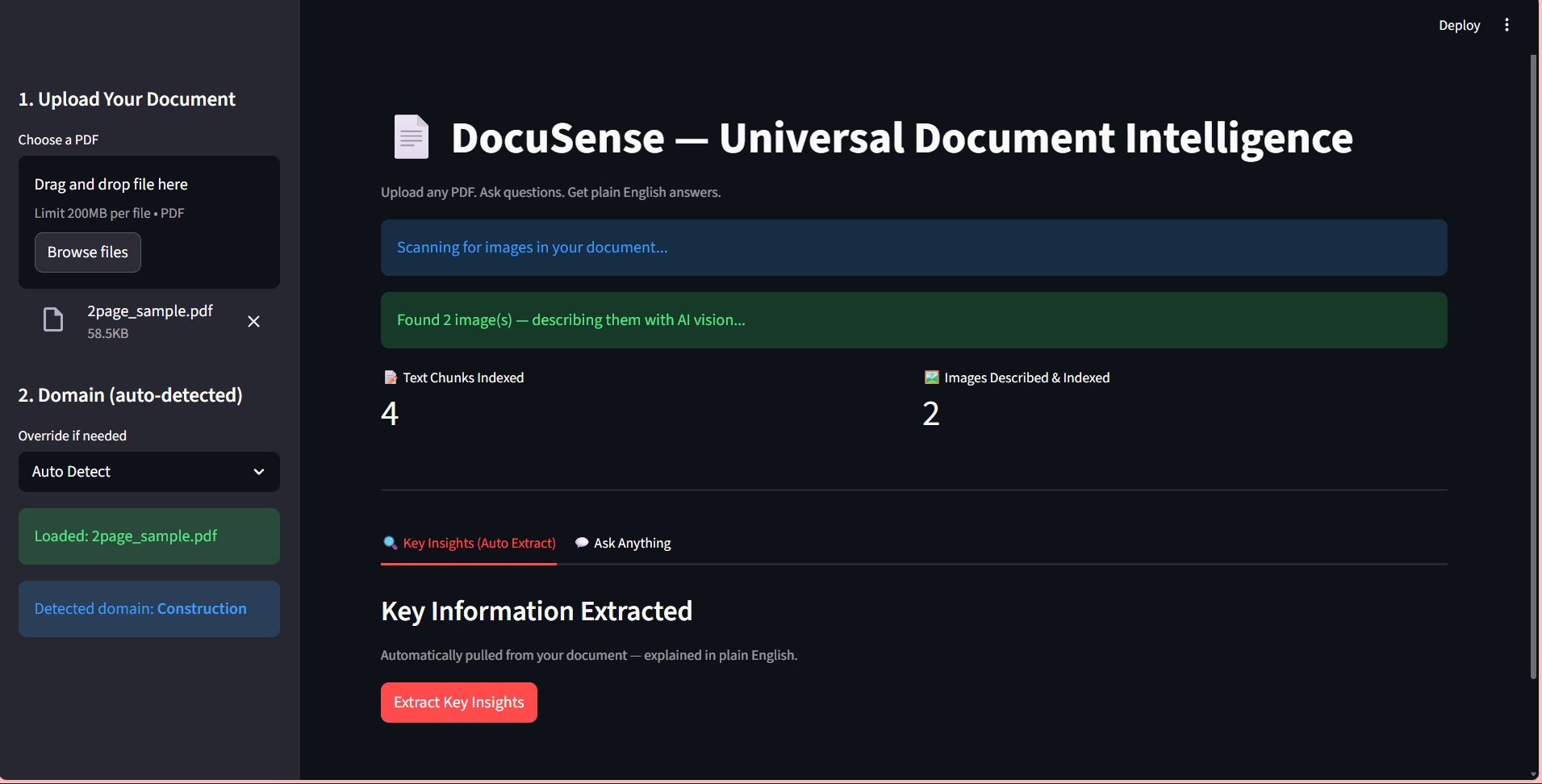
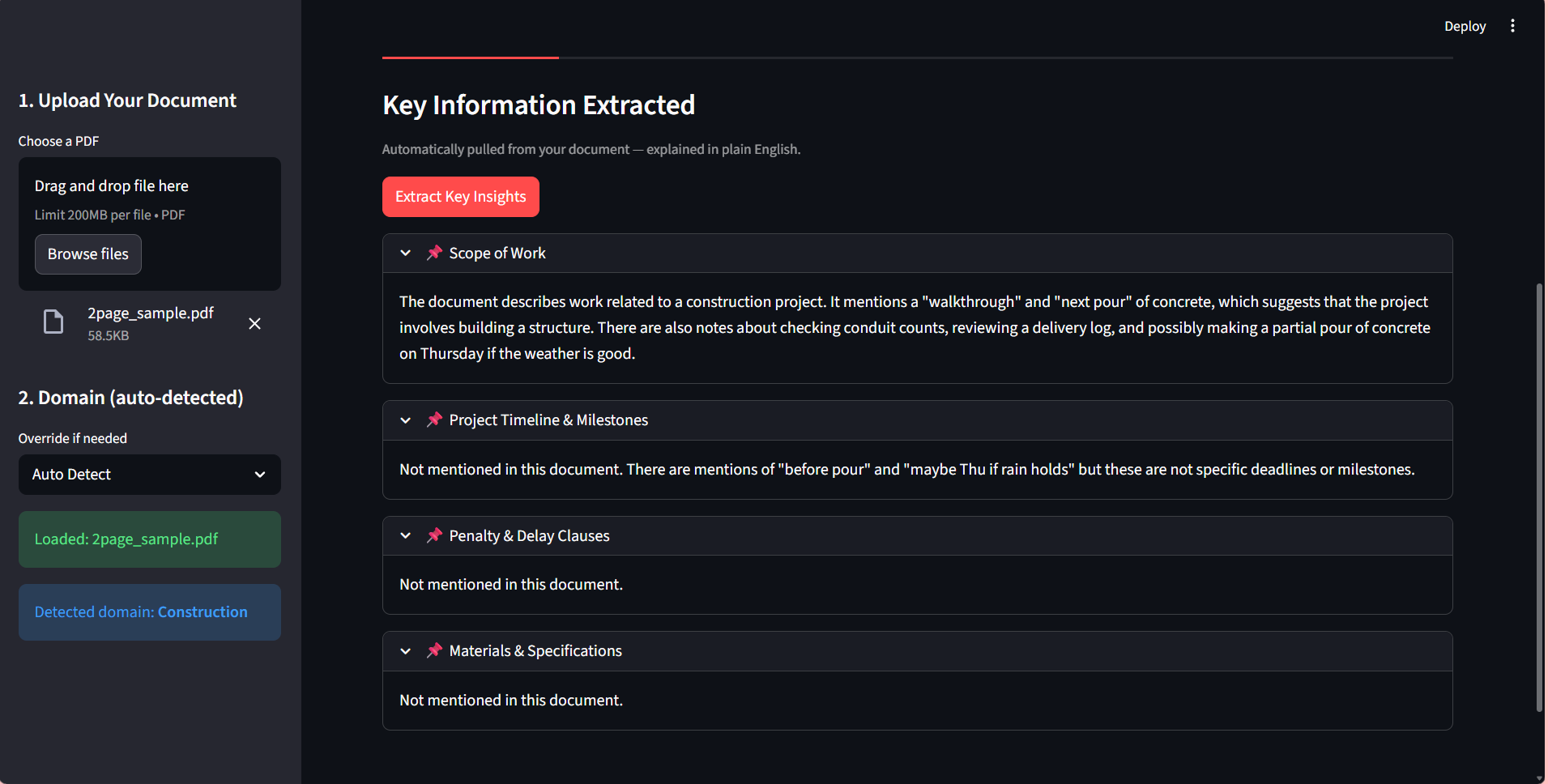
DOCUSENSE : RESEARCH AUTO
Extracting insights from complex financial contracts and reports was a slow, manual analyst process.
Developed a generative AI system using LangChain and HuggingFace to embed data into FAISS vector stores.
Reduced manual research effort by 40% while achieving 90%+ accuracy in automated clause extraction.
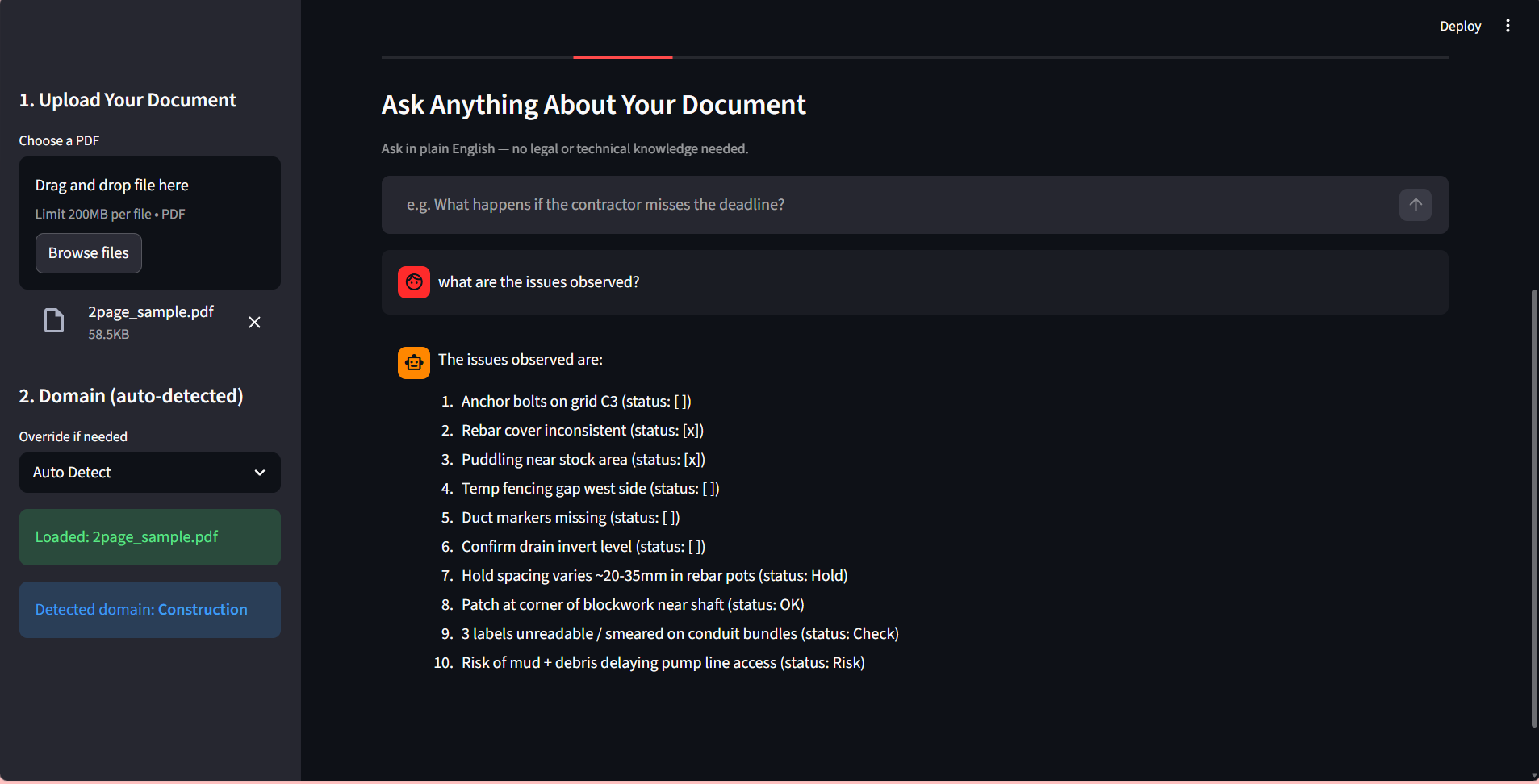
TRADEGPT : SIGNAL INTERPRETER
Market volatility signals are often difficult for human traders to interpret in real-time.
Built a fine-tuned Transformer system in PyTorch to translate price swings and news sentiment into reasoning.
Enhanced signal interpretability with 87% prediction accuracy and a 30% reduction in manual analysis.




04.Technical Publications
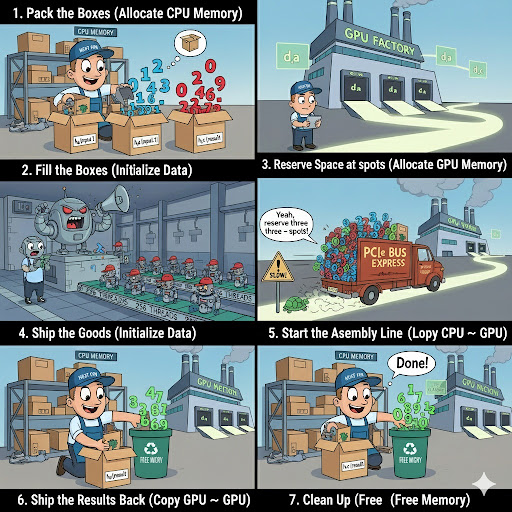
CUDA for AI — The GPU Whisperer
Why Your Graphics Card is Actually 10,000 Interns in a Trench Coat?

Part 4: Encapsulation, Polymorphism & Abstraction
Mastering the final three pillars of OOP before diving into AI and ML.

Part 3: Inheritance Deep Dive
Stop rewriting the same code: How to build modular and reusable AI systems.

Part 2: Stop Writing Spaghetti Code
The four pillars of Object-Oriented Programming that will save your sanity.

Part 1: Building Software Like a House
Python OOP Explained: Understanding the foundations of software architecture.
Professional Journey
Building intelligent systems, one algorithm at a time
AI/ML Engineer
Saayam For All
California, USA
Developed reinforcement learning agents using Multi-Armed Bandits and PPO for recommendation systems, increasing user engagement by 16% and reducing recommendation errors by 10%
Built Graph Attention Networks (GAT) to model social and knowledge graph relationships, improving link prediction accuracy by 20% and enabling personalized recommendations for 50K+ users
Fine-tuned pretrained LLMs (DistilBERT, T5) using PEFT techniques (LoRA/adapters) and integrated vector databases (FAISS, Pinecone) for embeddings, boosting task-specific F1-scores by 18% and reducing inference latency by 12%
Developed and deployed advanced generative AI systems leveraging LangChain, RAG, and Multi-Chain Prompting (MCP) to automate volunteer-requester matching, resource discovery, and intelligent assistance workflows, achieving high semantic relevance and 87%+ accuracy
Implemented end-to-end ML pipelines with Docker, FastAPI, and AWS, reducing deployment cycles from 3 weeks to 2 days and achieving sub-200ms end-to-end inference latency
Engineered robust evaluation frameworks for LLM outputs, including safety checks, statistical validation, and error analysis, reducing model failures by 92% and detecting 15+ critical issues across services
Built scalable generative AI pipelines on AWS, combining RAG-based retrieval and automated monitoring to track 20+ performance and quality metrics, maintaining 99.5% uptime for 1,000+ users
Machine Learning Engineer
Tata Consultancy Services
Verizon (Hyderabad, India)
Developed and fine-tuned machine learning models using scikit-learn, XGBoost, and Random Forest for regression and classification tasks, achieving 18–22% reduction in RMSE through advanced feature engineering and hyperparameter optimization
Built deep learning architectures with PyTorch, including CNNs for image recognition and LSTM/GRU networks for sequential text data, boosting model accuracy by 15% and lowering inference time by ~20%
Implemented extbf{GPU-accelerated training pipelines} for predictive maintenance applications, leveraging distributed computing and parallel processing to reduce training durations by 40% and detect failures proactively
Designed end-to-end NLP pipelines using TF-IDF, Word2Vec, GloVe embeddings, and early BERT fine-tuning, deploying scalable REST APIs with FastAPI, Docker, and AWS, improving F1-scores and cutting inference latency by 25–30%
Engineered data preprocessing and ETL workflows with Pandas, NumPy, and Apache Spark, handling large-scale datasets (10M+ records) efficiently and reducing data processing times by 35%
Collaborated with cross-functional teams to integrate ML models into production systems, ensuring seamless deployment and monitoring, resulting in a 20% increase in system reliability and user satisfaction
Let's Connect
Open to new opportunities, collaborations, and innovative AI projects. Let's build something amazing together.
Ready to Build Something Extraordinary?
Whether it's a challenging AI problem, a collaborative project, or an exciting opportunity – I'd love to hear from you.
Send a Message